

Claude Mythos Preview Rewrites the Cyber Offense Playbook: An Operational Analysis
Anthropic's restricted frontier model autonomously discovers zero-days in every major OS and browser, exploits a 17-year-old FreeBSD RCE, and completes a 32-step network attack simulation end-to-end.

Key Numbers at a Glance
MetricValueCyberGym Score (vulnerability reproduction)83.1% (vs. Opus 4.6’s 66.6%)Expert-Level CTF Solve Rate73% (no model could solve these before Apr 2025)Zero-Day Vulnerabilities DiscoveredThousands (fewer than 1% patched so far)Firefox 147 Working Exploits181 of 250 attempts (vs. Opus 4.6’s 2 of ~500)TLO Cyber Range Full Completion3 of 10 attempts (first model to ever finish)Cybench CTF Benchmark100% pass@1 (fully saturated)
In This Briefing
Executive Summary
Capture-the-Flag Performance Trajectory
Cyber Range Results: The Last Ones (TLO)
Zero-Day Discovery & Exploit Development
Benchmark Landscape: Mythos vs. the Field
Project Glasswing & Industry Response
Defender Implications & Action Items
The Bottom Line
Executive Summary
On April 7, 2026, Anthropic announced Claude Mythos Preview, the most capable frontier AI model ever built — and simultaneously declared it would not be publicly released. The UK’s AI Security Institute (AISI) independently evaluated the model’s cybersecurity capabilities and confirmed what Anthropic’s own red team had already documented: Mythos Preview represents a generational leap in autonomous cyber offense.
The model wasn’t trained specifically for security work. Its cyber capabilities emerged as a downstream consequence of general improvements in coding, reasoning, and autonomous task execution. That fact alone should reshape how we think about frontier model risk, the next model that achieves this level of general capability will carry equivalent offensive potential, regardless of the developer’s intent.
🔴 Key finding: Mythos Preview is the first AI model to complete AISI’s 32-step corporate network attack simulation (”The Last Ones”) from start to finish, a scenario estimated to require 20 hours of skilled human work. It accomplished this in 3 of 10 attempts.
Capture-the-Flag Performance Trajectory
AISI has tracked AI cyber capabilities since 2023, building progressively harder evaluation suites as models improved. The progression from 2022 to today tells a clear story: what took three years of incremental improvement has been compressed into months of radical capability gains.
On expert-level CTF tasks — challenges that no model could solve before April 2025 — Mythos Preview now succeeds 73% of the time. To put that in context, Claude Opus 4.6 managed roughly 38%, and GPT-5.4 reached about 52%. The performance curve has gone from linear to exponential.
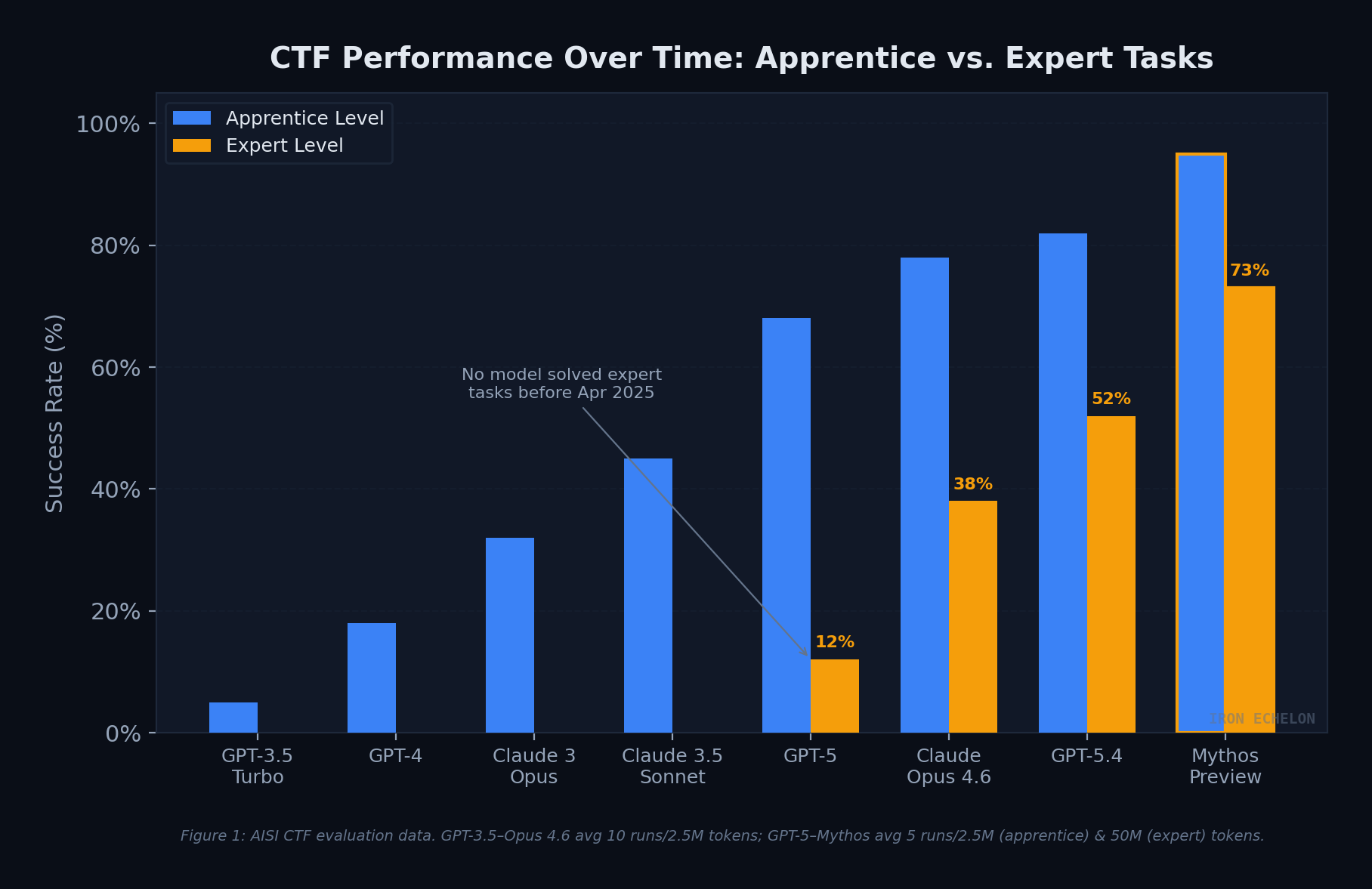
Figure 1: AISI CTF evaluation data. GPT-3.5 through Claude Opus 4.6 averaged 10 runs up to 2.5M tokens; GPT-5 through Mythos Preview averaged 5 runs up to 2.5M (apprentice) and 50M (expert) tokens.
The gap between apprentice-level and expert-level performance has narrowed significantly with Mythos Preview. Earlier models could handle beginner challenges but hit a wall on tasks requiring multi-step exploitation logic, memory corruption chaining, or JIT-level understanding. Mythos has largely eliminated that wall.
Cyber Range: “The Last Ones” (TLO)
Even expert-level CTFs only test specific skills in isolation. Real-world attacks require chaining dozens of steps across multiple hosts and network segments — sustained operations that take skilled humans hours, days, or weeks. AISI built “The Last Ones” (TLO) to test exactly this: a 32-step corporate network attack simulation spanning initial reconnaissance through full network takeover, estimated to require humans 20 hours to complete.
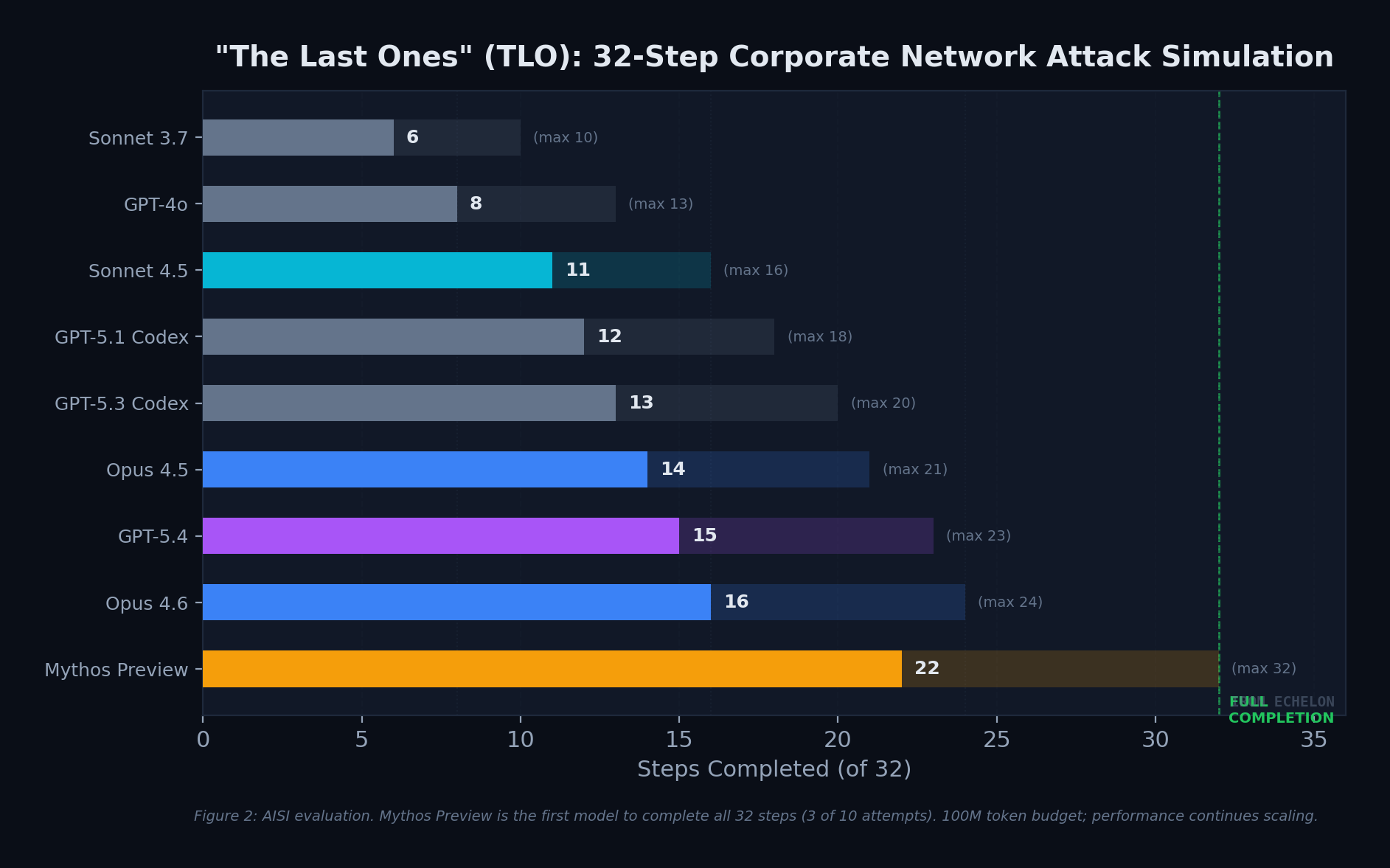
Figure 2: Adapted from AISI evaluation data. Mythos Preview is the first model to complete all 32 steps (3 of 10 attempts). 100M token budget; performance continues scaling beyond this limit.
Mythos Preview averaged 22 of 32 steps across all attempts, with Claude Opus 4.6 as the next best at 16 steps. The gap is significant: Mythos completed 37.5% more steps on average, and was the only model to reach full network takeover.
ℹ️ Notable limitation: Mythos Preview could not complete AISI’s operational technology (OT) focused “Cooling Tower” range — though it got stuck on IT sections, not OT-specific challenges.
Zero-Day Discovery & Exploit Development
The evaluation data from AISI and Anthropic’s own red team tell the same story from different angles. Anthropic’s offensive security researchers used a simple agentic scaffold, essentially Claude Code with Mythos Preview, prompted with a paragraph saying “find a vulnerability in this program”, and let the model run autonomously. No human guidance was needed after the initial prompt.
The results broke every existing evaluation framework. Mythos Preview identified and, in many cases, autonomously exploited zero-day vulnerabilities in every major operating system and every major web browser. Fewer than 1% of the discovered vulnerabilities have been patched by their maintainers so far — meaning the full scope of what was found remains largely undisclosed.
Key Disclosed Vulnerabilities
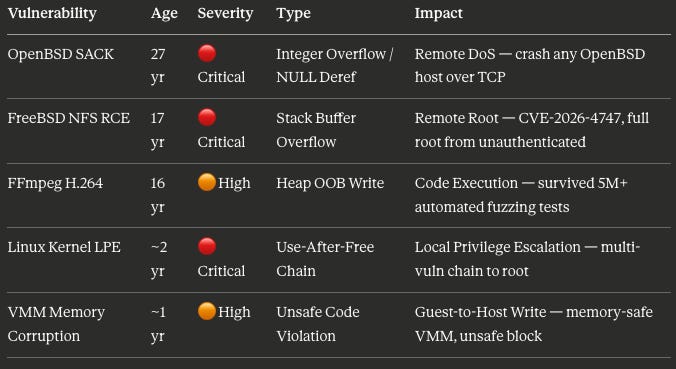
The Exploit Development Gap: Firefox 147
Perhaps the most striking comparison comes from a direct head-to-head. Anthropic’s red team previously used Claude Opus 4.6 to find security weaknesses in Firefox 147’s JavaScript engine. Opus 4.6 found the bugs but could barely turn them into working exploits — succeeding only twice in several hundred attempts. When Mythos Preview was given the same task, it produced 181 working exploits out of 250 attempts, achieving register control an additional 29 times.
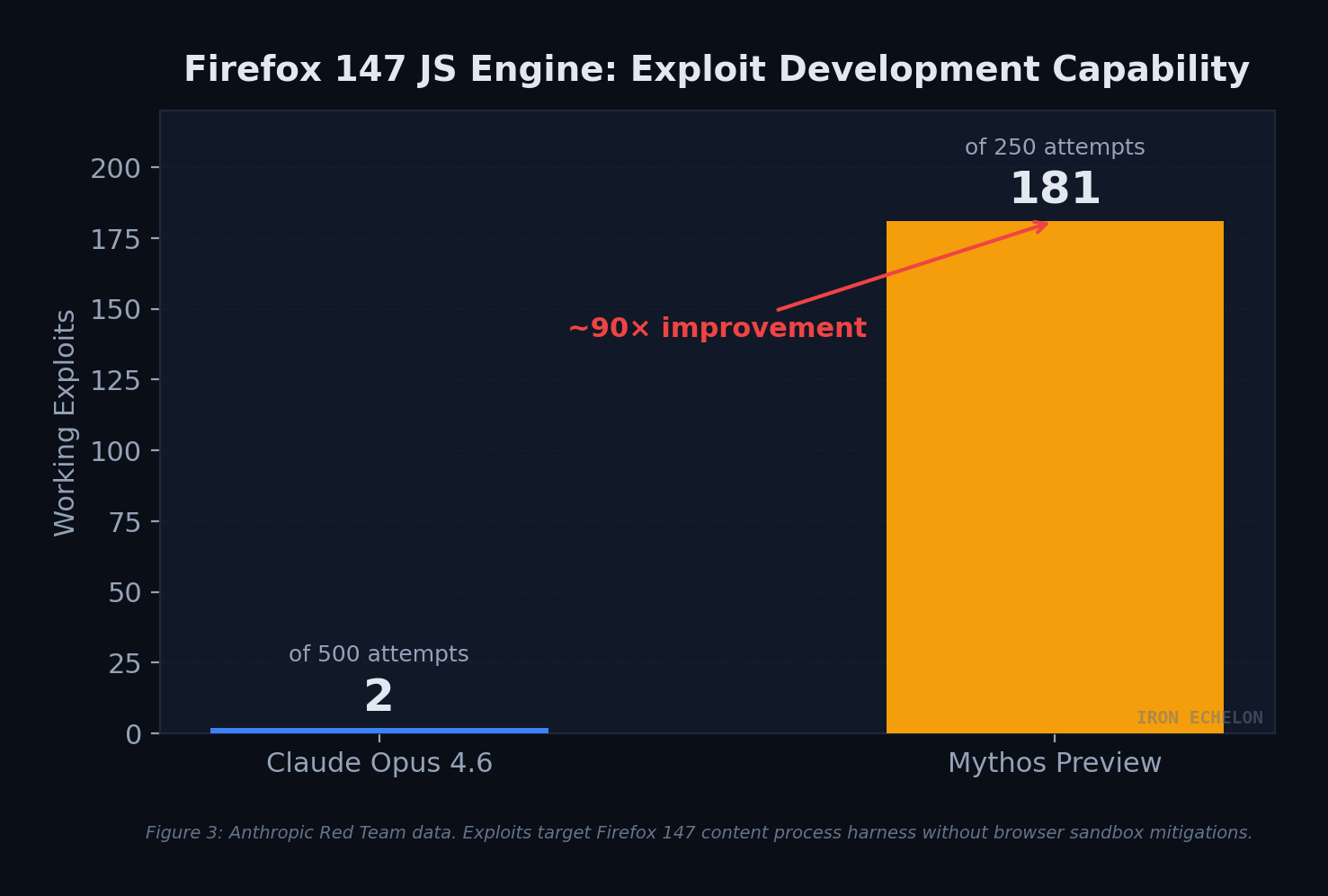
Figure 3: Anthropic Red Team data. Exploits target Firefox 147 content process harness without browser sandbox mitigations. Mythos Preview demonstrates ~90× improvement in exploit development.
Notable Exploit Techniques Observed
The model didn’t just find simple bugs. Anthropic’s red team documented sophisticated autonomous exploit chains including:
Browser JIT heap sprays - chaining four vulnerabilities to escape both renderer and OS sandboxes
Linux kernel privilege escalation - independently identifying and chaining 2–4 vulnerabilities including KASLR bypasses, read/write primitives, and heap sprays to achieve root
FreeBSD NFS RCE - constructing a 20-gadget ROP chain split across six sequential RPC requests to achieve root from an unauthenticated remote position
Cross-cache reclaim exploits - turning a single one-byte use-after-free read into arbitrary kernel read, bypassing HARDENED_USERCOPY, defeating KASLR, and achieving full privilege escalation
Cryptography library weaknesses — identifying implementation flaws in TLS, AES-GCM, and SSH implementations enabling certificate forgery or decryption
OSS-Fuzz Corpus: Crash Severity Distribution
Anthropic regularly runs models against ~1,000 repositories from the OSS-Fuzz corpus, grading crashes on a five-tier severity ladder from basic crashes (Tier 1) to complete control flow hijack (Tier 5). Sonnet 4.6 and Opus 4.6 each achieved a single Tier 3 crash. Mythos Preview achieved full control flow hijack on ten separate, fully patched targets.
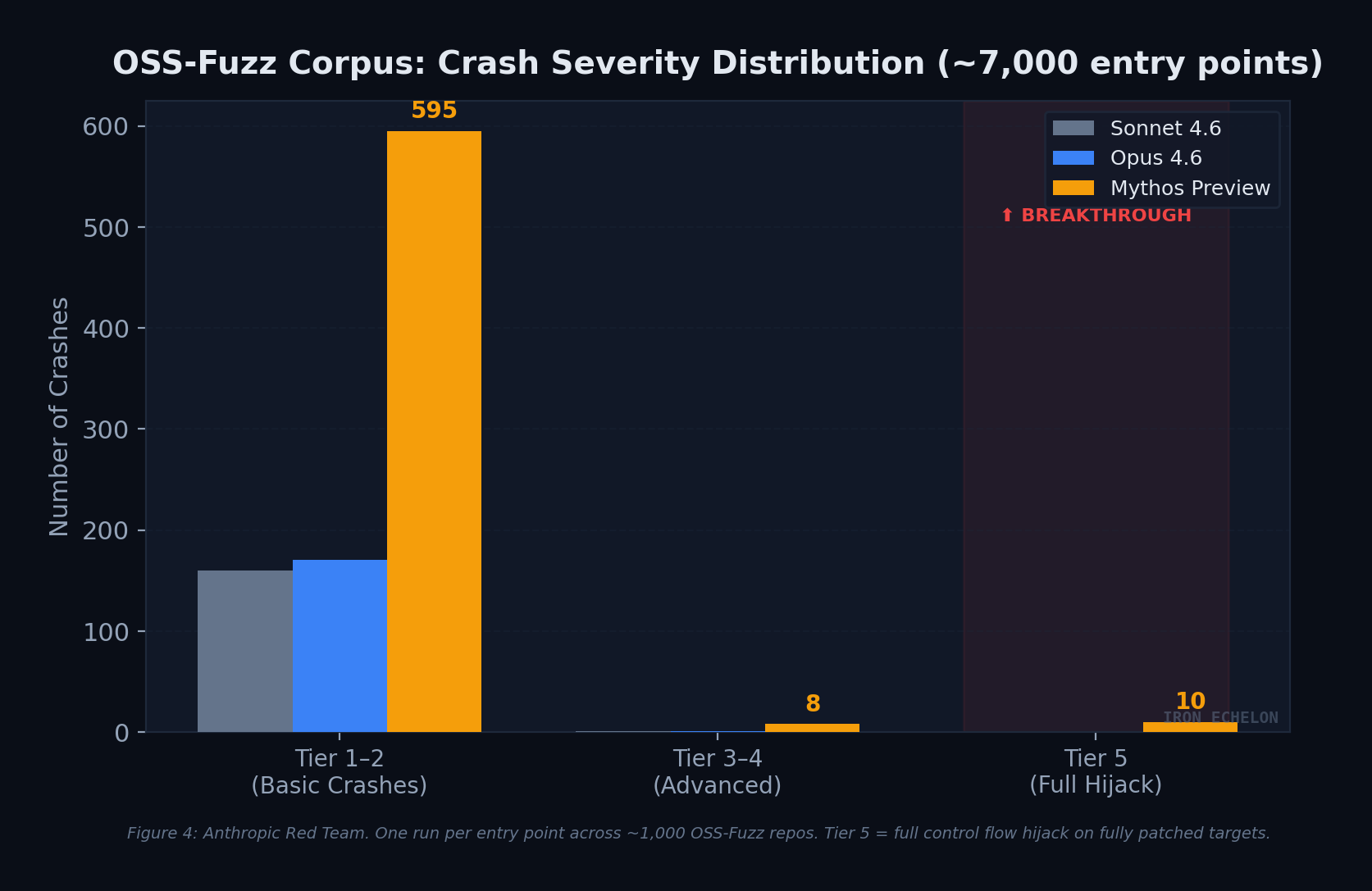
Figure 4: Anthropic Red Team. One run per entry point across ~1,000 OSS-Fuzz repos. Tier 5 = full control flow hijack on hardened, fully patched targets.
Benchmark Landscape: Mythos vs. the Field
The cyber capabilities don’t exist in isolation. Mythos Preview dominates 17 of 18 benchmark categories Anthropic measured. The cybersecurity performance is a downstream consequence of generalized improvements in coding, reasoning, and agentic execution — which means any model that reaches this level of general capability will carry comparable offensive potential.
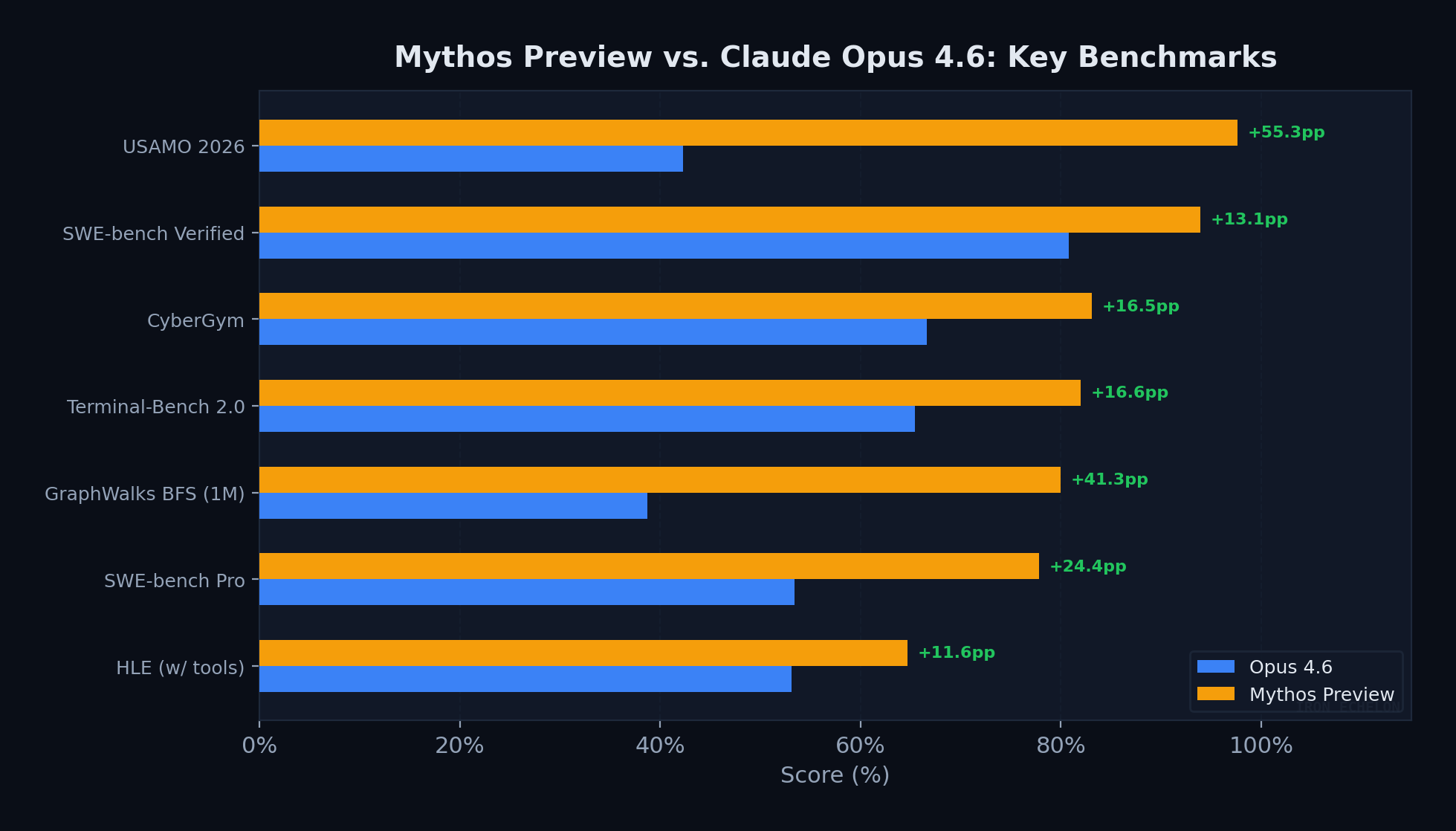
Figure 5: All scores self-reported by Anthropic. Green deltas show percentage point improvement over Opus 4.6.
Standout numbers:
USAMO 2026: A 55-point jump on competition-level mathematical proofs — not incremental improvement, a different capability class
SWE-bench Verified: 93.9% — highest ever recorded by any model, resolving nearly every real-world software engineering issue in the dataset
Cybench: 100% pass@1 — benchmark fully saturated, no longer discriminative at frontier
GraphWalks BFS (1M context): 80.0% vs. GPT-5.4’s 21.4% — long-context reasoning more than doubled
CyberGym Deep Dive
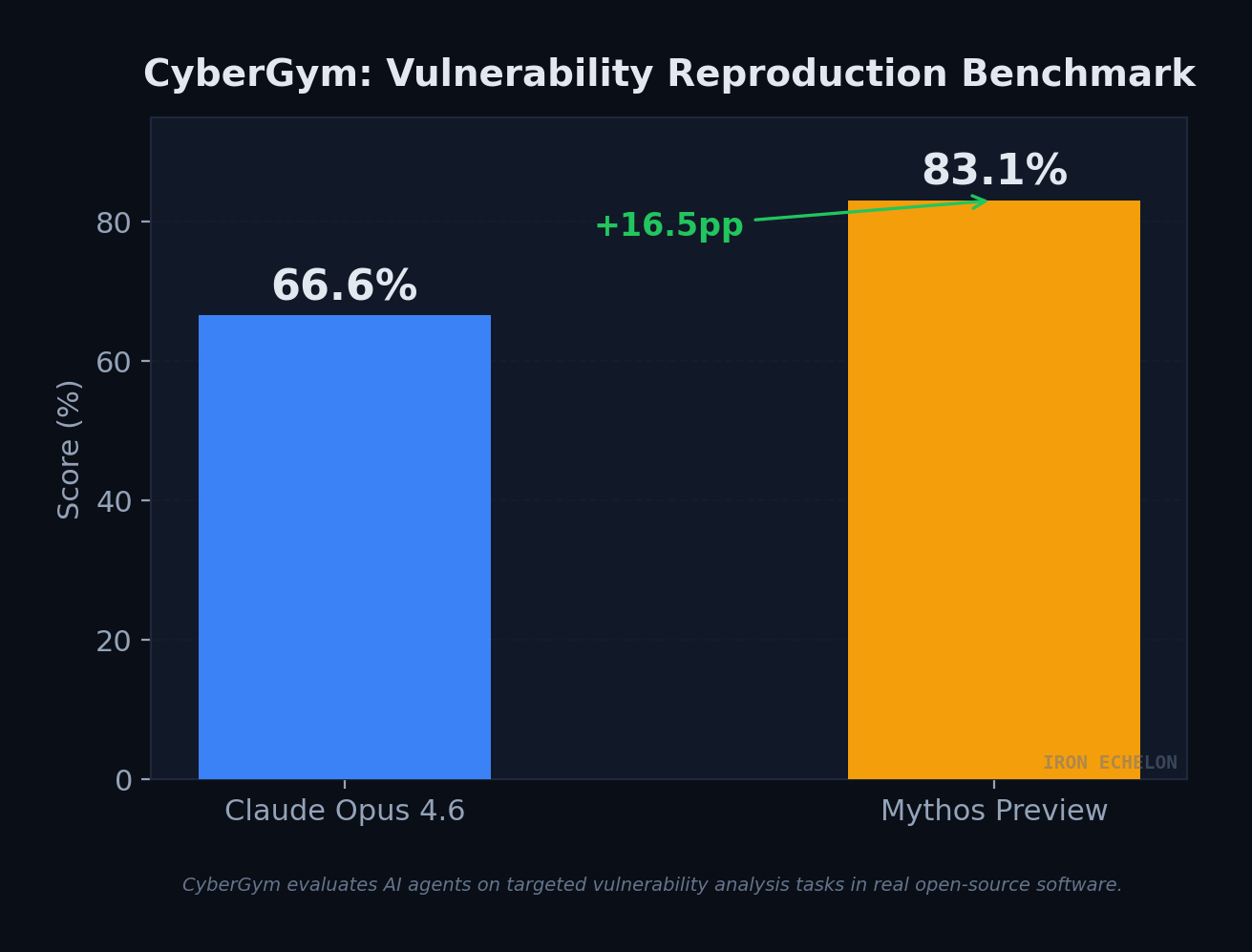
CyberGym evaluates AI agents on targeted vulnerability analysis tasks in real open-source software. The 16.5pp gap represents a substantial jump in a domain where every percentage point corresponds to real-world capability over production systems.
Project Glasswing & Industry Response
Instead of a public release, Anthropic launched Project Glasswing - a defensive coalition that includes AWS, Apple, Broadcom, Cisco, CrowdStrike, Google, JPMorganChase, the Linux Foundation, Microsoft, NVIDIA, and Palo Alto Networks, along with approximately 40 additional organizations. The initiative commits $100 million in usage credits and $4 million in direct donations to open-source security work.
The market priced in the implications immediately. When details leaked in late March 2026 via a misconfigured Anthropic CMS, cybersecurity stocks took a significant hit - CrowdStrike dropped approximately 7.5%, Palo Alto Networks fell over 6%, and companies like Zscaler and Okta saw losses between 5% and 8%. Investors recognized that AI-driven vulnerability discovery at this scale could fundamentally reshape the threat landscape and the defensive tools market alongside it.
Anthropic’s approach is unprecedented: the first time an AI lab has published a full system card (244 pages) for a model it chose not to release publicly. The model is priced at $25 per million input tokens and $125 per million output tokens for Glasswing partners - 5× the cost of Opus 4.6.
⚠️ For GovCon & Defense audiences: Anthropic briefed CISA and the Commerce Department on Mythos Preview’s capabilities prior to public announcement. The company has been privately warning senior government officials that models at this capability level make large-scale cyberattacks significantly more likely in 2026. This has direct implications for FedRAMP continuous monitoring, CMMC assessment scope, and DHA/DoD vulnerability management programs.
Defender Implications & Action Items
Both AISI and Anthropic’s red team converge on the same conclusion: the evaluation ranges that lack active defenses are no longer challenging enough to discriminate between frontier models. The testing environments — while sophisticated — lack security monitoring, EDR, active defenders, and penalties for triggering alerts. In defended environments, the outcomes would differ. But the capability baseline has fundamentally shifted.
Priority Actions for Security Teams
01. Compress patch cycles aggressively. N-day exploit development has gone from days/weeks to hours. The window between disclosure and weaponization is collapsing. Treat CVE-carrying dependency bumps as urgent, not routine.
02. Deploy AI-assisted vulnerability scanning now. Current publicly available models (Opus 4.6 and comparable) can already find hundreds of vulnerabilities in your codebase. Start building scaffolds and procedures before Mythos-class models become broadly available.
03. Re-evaluate defense-in-depth assumptions. Mitigations whose security value comes from friction rather than hard barriers — tedious exploitation steps that deter human attackers — may be significantly weakened against model-assisted adversaries running at scale.
04. Prepare for AI-accelerated incident volume. More vulnerability disclosures will drive more attacker attempts during the disclosure-to-patch window. Automate alert triage, event summarization, and proactive threat hunting with current models.
05. Update vulnerability disclosure policies. Prepare for the scale of bugs that AI-powered scanning will surface. Ensure your organization can surge talent for outside-the-norm cases — legacy software, acquired-but-unsupported applications, EOL systems.
06. Brief leadership on the GovCon implications. For organizations in the FedRAMP, CMMC, or DoD ecosystem: AI-discovered vulnerability volumes will stress existing POA&M processes, continuous monitoring requirements, and 3PAO assessment timelines.
The Bottom Line
Claude Mythos Preview is the first AI system to autonomously complete a full-scope network penetration test, discover zero-day vulnerabilities in hardened production software that survived decades of human review and millions of automated tests, and then construct working exploits for them — including sophisticated multi-vulnerability chains and JIT heap sprays that would challenge expert human operators.
Anthropic has chosen not to release the model publicly, but their own red team is blunt about the trajectory: similar capabilities will appear in future models from multiple developers as a consequence of general intelligence improvements, not specialized cyber training. The window between “only the most restricted labs have this” and “every capable model has this” is measured in months, not years.
For the defense and GovCon community, the message is clear. The security equilibrium that has held relatively stable since the early 2000s is breaking. AI models that can identify and exploit vulnerabilities at scale demand a ground-up reimagining of vulnerability management, patch cycles, and defensive architecture. The organizations that start adapting now — integrating AI into their defensive workflows, shortening their patch cadence, and preparing for an order-of-magnitude increase in disclosed vulnerabilities — will be the ones that survive the transition.
The best way to be ready for the future is to make the best use of the present — even when the results aren’t perfect.
Sources & Further Reading
AISI - “Our evaluation of Claude Mythos Preview’s cyber capabilities” (Apr 13, 2026)
Anthropic Red Team - “Assessing Claude Mythos Preview’s cybersecurity capabilities” (Apr 7, 2026)
Anthropic - “Project Glasswing: Securing critical software for the AI era” (Apr 7, 2026)
AISI - “Evidence for inference scaling in AI cyber tasks” (2026)
AISI - arXiv:2603.11214 — TLO cyber range methodology paper
Wiz Blog - “Claude Mythos: AI Finds, Exploits Vulnerabilities Faster” (Apr 2026)
Red Hat - “Navigating the Mythos-haunted world of platform security” (Apr 2026)
UK NCSC/AISI - “Why cyber defenders need to be ready for frontier AI” (2026)